



倒排索引原理
倒排索引来源于搜索引擎的技术,可以说是搜索引擎的基石。正是有了倒排索引技术,搜索引擎才能有效率的进行数据库查找、删除等操作。在详细说明倒排索引之前,我们说一下与之相关的正排索引并与之比较。
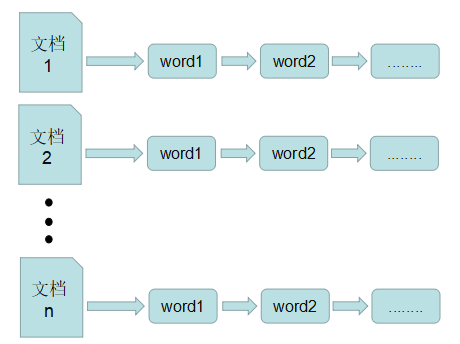
正排索引
在搜索引擎中,正排表是以文档的 ID 为关键字,表中记录文档中每个字的位置信息,查找时扫描表中每个文档中字的信息直到找出所有包含查询关键字的文档。
正排表结构如下图所示,这种组织方法在建立索引的时候结构比较简单,建立比较方便且易于维护; 因为索引是基于文档建立的,若是有新的文档加入,直接为该文档建立一个新的索引块,挂接在原来索引文件的后面。若是有文档删除,则直接找到该文档号文档对应的索引信息,将其直接删除。但是在查询的时候需对所有的文档进行扫描以确保没有遗漏,这样就使得检索时间大大延长,检索效率低下。
尽管正排表的工作原理非常的简单,但是由于其检索效率太低,除非在特定情况下,否则实用性价值不大。
倒排索引
倒排表以字或词为关键字进行索引,表中关键字所对应的记录表项记录了出现这个字或词的所有文档。
由于每个字或词对应的文档数量在动态变化,所以倒排表的建立和维护都较为复杂,但是在查询的时候由于可以一次得到查询关键字所对应的所有文档,所以效率高于正排表。在全文检索中,检索的快速响应是一个最为关键的性能,而索引建立由于在后台进行,尽管效率相对低一些,但不会影响整个搜索引擎的效率。
倒排表的结构图如下图: 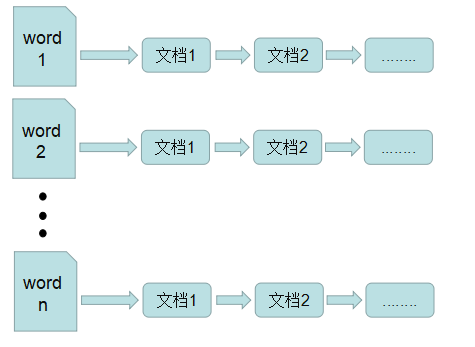
PostgreSQL 中的 Gin 索引
概述
GIN 是 Generalized Inverted Index 的缩写。就是所谓的倒排索引。它处理的数据类型的值不是原子的,而是由元素构成。我们称之为复合类型。如 (‘hank’, ‘15:3 21:4’) 中,表示 hank 在 15:3 和 21:4 这两个位置出现过, 下面会从具体的例子更加清晰的认识 GIN 索引。
GIN 索引结构
物理结构
GIN 索引在物理存储上包含如下内容:
1. Entry:GIN索引中的一个元素,可以认为是一个词位,也可以理解为一个key
2. Entry tree:在Entry上构建的B树
3. posting list:一个Entry出现的物理位置(heap ctid, 堆表行号)的链表
4. posting tree:在一个Entry出现的物理位置链表(heap ctid, 堆表行号)上构建的B树,所以posting tree的KEY是ctid,而entry tree的KEY是被索引的列的值
5. pending list:索引元组的临时存储链表,用于fastupdate模式的插入操作
从上面可以看出 GIN 索引主要由 Entry tree 和 posting tree(or posting list)组成,其中 Entry tree 是 GIN 索引的主结构树,posting tree 是辅助树。
entry tree 类似于 b+tree,而 posting tree 则类似于 b-tree。
另外,不管 entry tree 还是 posting tree,它们都是按 KEY 有序组织的。
逻辑结构
GIN 索引在逻辑上可以看成一个 relation,该 relation 有两种结构:
- 只索引基表的一列
| key | value |
| —- | ——————————- |
| key1 | Posting list (or posting tree) |
| key2 | Posting list (or posting tree) |
| … | … |
- 索引基表的多列 (复合、多列索引)
| column_id | key | value |
| ———– | —- | ——————————- |
| Column1 num | key1 | Posting list (or posting tree) |
| Column2 num | key1 | Posting list (or posting tree) |
| Column3 num | key1 | Posting list (or posting tree) |
| … | … | … |
那我们可以知道在这种结构下,对于基表中不同列的相同的 key,在 GIN 索引中也会当作不同的 key 来处理。
全文检索
GIN 的主要应用领域是加速全文搜索,所以,这里我们使用全文搜索的例子介绍一下 GIN 索引。
建一张表, doc_tsv 是文本搜索类型,可以自动排序并消除重复的元素:
PostgreSQL tsvector 文档链接:http://www.postgres.cn/docs/9.6/datatype-textsearch.html
pg_study=# create table ts(doc text, doc_tsv tsvector);
CREATE TABLE
pg_study=# insert into ts(doc) values
('Can a sheet slitter slit sheets?'),
('How many sheets could a sheet slitter slit?'),
('I slit a sheet, a sheet I slit.'),
('Upon a slitted sheet I sit.'),
('Whoever slit the sheets is a good sheet slitter.'),
('I am a sheet slitter.'),
('I slit sheets.'),
('I am the sleekest sheet slitter that ever slit sheets.'),
('She slits the sheet she sits on.');
INSERT 0 9
pg_study=# update ts set doc_tsv = to_tsvector(doc);
UPDATE 9
pg_study=# create index on ts using gin(doc_tsv);
CREATE INDEX
该 GIN 索引结构如下,黑色方块是 TID 编号,白色为单词, 注意这里是单向链表,不同于 B-tree 的双向链表:
PostgreSQL tid ,ctid 参考链接:
https://blog.csdn.net/weixin_34372728/article/details/90591262
https://help.aliyun.com/document_detail/181315.html
https://cloud.tencent.com/developer/article/1555364
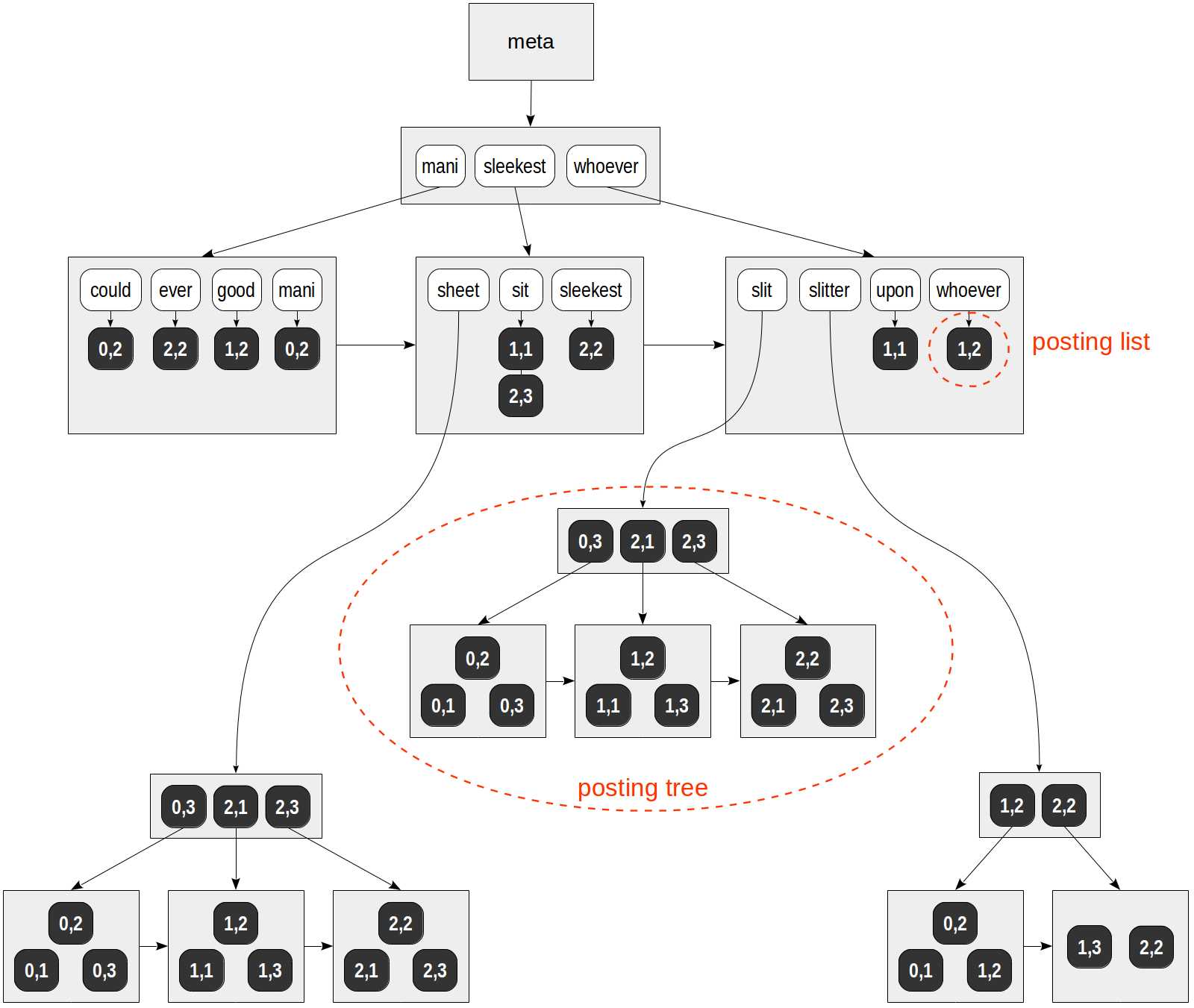
我们再看下面这个例子:
pg_study=# select ctid,doc, doc_tsv from ts;
ctid | doc | doc_tsv
--------+--------------------------------------------------------+---------------------------------------------------------
(0,10) | Can a sheet slitter slit sheets? | 'sheet':3,6 'slit':5 'slitter':4
(0,11) | How many sheets could a sheet slitter slit? | 'could':4 'mani':2 'sheet':3,6 'slit':8 'slitter':7
(0,12) | I slit a sheet, a sheet I slit. | 'sheet':4,6 'slit':2,8
(0,13) | Upon a slitted sheet I sit. | 'sheet':4 'sit':6 'slit':3 'upon':1
(0,14) | Whoever slit the sheets is a good sheet slitter. | 'good':7 'sheet':4,8 'slit':2 'slitter':9 'whoever':1
(0,15) | I am a sheet slitter. | 'sheet':4 'slitter':5
(0,16) | I slit sheets. | 'sheet':3 'slit':2
(0,17) | I am the sleekest sheet slitter that ever slit sheets. | 'ever':8 'sheet':5,10 'sleekest':4 'slit':9 'slitter':6
(0,18) | She slits the sheet she sits on. | 'sheet':4 'sit':6 'slit':2
(9 rows)
由上可见,sheet, slit, slitter 出现在多行之中,所有会有多个 TID,这样就会生成一个 TID 列表,并为之生成一棵单独的 B-tree。
以下语句可以找出多少行出现过该单词。
pg_study=# select (unnest(doc_tsv)).lexeme, count(*) from ts
group by 1 order by 2 desc;
lexeme | count
----------+-------
sheet | 9
slit | 8
slitter | 5
sit | 2
upon | 1
mani | 1
whoever | 1
sleekest | 1
good | 1
could | 1
ever | 1
(11 rows)
查询示例
下面的查询如何执行呢?
// 这里由于数据量较小,所以禁用全表扫描
pg_study=# set enable_seqscan TO off;
SET
pg_study=# explain(costs off)
select doc from ts where doc_tsv @@ to_tsquery('many & slitter');
QUERY PLAN
---------------------------------------------------------------------
Bitmap Heap Scan on ts
Recheck Cond: (doc_tsv @@ to_tsquery('many & slitter'::text))
-> Bitmap Index Scan on ts_doc_tsv_idx
Index Cond: (doc_tsv @@ to_tsquery('many & slitter'::text))
(4 rows)
EXPLAIN
首先从查询中抽取出每个单词(查询 key):mani 和 slitter。这由特殊的 API 完成,它会考虑数据类型和操作符的策略:
pg_study=# select amop.amopopr::regoperator, amop.amopstrategy
from pg_opclass opc, pg_opfamily opf, pg_am am, pg_amop amop
where opc.opcname = 'tsvector_ops'
and opf.oid = opc.opcfamily
and am.oid = opf.opfmethod
and amop.amopfamily = opc.opcfamily
and am.amname = 'gin'
and amop.amoplefttype = opc.opcintype;
amopopr | amopstrategy
-----------------------+--------------
@@(tsvector,tsquery) | 1
@@@(tsvector,tsquery) | 2
(2 rows)
在包含单词的 B-tree 中,找出两个 key 对应的 TID 列表:
mani:(0,2)
slitter:(0,1), (0,2), (1,2), (1,3), (2,2)
最后,对每个找出的 TID,依次调用一致性函数。这个一致性函数可以确定 TID 指向的行是否满足查询条件。因为查询中的单词用 and 连接,因此返回的行仅仅是 (0,2)。
| | | consistency
| | | function
TID | mani | slitter | slit & slitter
-------+------+---------+----------------
(0,1) | f | T | f
(0,2) | T | T | T
(1,2) | f | T | f
(1,3) | f | T | f
(2,2) | f | T | f
结果是:
pg_study=# select doc from ts where doc_tsv @@ to_tsquery('many & slitter');
doc
---------------------------------------------
How many sheets could a sheet slitter slit?
(1 row)
搜索运算符参考文档: http://www.postgres.cn/docs/9.6/functions-textsearch.html
更新速度慢的问题
GIN 索引中的数据插入或更新非常慢。因为每行通常包含许多要索引的单词元素。因此,当添加或更新一行时,我们必须大量更新索引树。
另一方面,如果同时更新多个行,它们的某些单词元素可能是相同的,所以总的代价小于一行一行单独更新文档时的代价。
GIN 索引具有 fastupdate 存储参数,我们可以在创建索引时指定它,并在以后更新:
pg_study=# create index on ts using gin(doc_tsv) with (fastupdate = true);
CREATE INDEX
fastupdate 参考链接: https://www.cnblogs.com/flying-tiger/p/6704931.html
启用此参数后,更新将累积在单独的无序列表中。当此列表足够大时或 vacuum(垃圾回收)期间,所有累积的更新将立即对索引操作。这个“足够大”的列表由“ gin_pending_list_limit”配置参数或创建索引时同名的存储参数确定。
部分匹配搜索
查询包含 slit 打头的 doc
pg_study=# select doc from ts where doc_tsv @@ to_tsquery('slit:*');
doc
--------------------------------------------------------
Can a sheet slitter slit sheets?
How many sheets could a sheet slitter slit?
I slit a sheet, a sheet I slit.
Upon a slitted sheet I sit.
Whoever slit the sheets is a good sheet slitter.
I am a sheet slitter.
I slit sheets.
I am the sleekest sheet slitter that ever slit sheets.
She slits the sheet she sits on.
(9 rows)
同样可以使用索引加速:
pg_study=# explain (costs off)
select doc from ts where doc_tsv @@ to_tsquery('slit:*');
QUERY PLAN
---------------------------------------------------
Seq Scan on ts
Filter: (doc_tsv @@ to_tsquery('slit:*'::text))
(2 rows)
EXPLAIN
关键词的频繁程度
制造一些数据, 下载地址:https://blog-1254305550.cos.ap-beijing.myqcloud.com/mail_messages.sql.gz
fts=# alter table mail_messages add column tsv tsvector;
fts=# update mail_messages set tsv = to_tsvector(body_plain);
fts=# create index on mail_messages using gin(tsv);
fts=# \timing on
-- 共356125条数据
fts=# select count(*) from mail_messages;
count
--------
356125
(1 row)
--这里不使用unnest统计单词出现在行的次数,因为数据量比较大,我们使用ts_stat函数来进行计算
fts=# select word, ndoc
fts-# from ts_stat('select tsv from mail_messages')
fts-# order by ndoc desc limit 3;
word | ndoc
-------+--------
wrote | 231174
use | 173833
would | 157169
(3 rows)
Time: 11556.976 ms
例如我们查询邮件信息里很少出现的单词,如“tattoo”:
fts=# select word, ndoc from ts_stat('select tsv from mail_messages') where word = 'tattoo';
word | ndoc
--------+------
tattoo | 2
(1 row)
Time: 11236.340 ms
两个单词同一行出现的次数,wrote 和 tattoo 同时出现的行只有一行
fts=# select count(*) from mail_messages where tsv @@ to_tsquery('wrote & tattoo');
count
-------
1
(1 row)
Time: 0.550 ms
我们来看看是如何执行的,如上所述,如果我们要获得两个词的 TID 列表,则搜索效率显然很低下:因为将必须遍历 20 多万个值,而只取一个值。但是通过统计信息,该算法可以了解到“wrote”经常出现,而“ tattoo”则很少出现。因此,将执行不经常使用的词的搜索,然后从检索到的两行中检查是否存在“wrote”。这样就可以快速得出查询结果:
fts=# select count(*) from mail_messages where tsv @@ to_tsquery('wrote & tattoo');
count
-------
1
(1 row)
Time: 0.419 ms
单独查询 wrote 将花费更长的时间
fts=# select count(*) from mail_messages where tsv @@ to_tsquery('wrote');
count
--------
231174
(1 row)
Time: 816.528 ms
这种优化当然不只是两个单词元素搜索有效,其他更复杂的搜索也有效。
限制查询结果
GIN 索引的一个特点是:它只能返回 bitmap,不能依次返回每个 TID。所以,本文中所有的计划都使用了 bitmap scan。
因此,使用 LIMIT 子句时效率不高。注意操作的预计成本(LIMIT 算子的 cost 字段):
fts=# explain (costs on) select * from mail_messages where tsv @@ to_tsquery('wrote') limit 1;
QUERY PLAN
----------------------------------------------------------------------------------------------
Limit (cost=34.05..37.98 rows=1 width=1024)
-> Bitmap Heap Scan on mail_messages (cost=34.05..7032.82 rows=1781 width=1024)
Recheck Cond: (tsv @@ to_tsquery('wrote'::text))
-> Bitmap Index Scan on mail_messages_tsv_idx (cost=0.00..33.60 rows=1781 width=0)
Index Cond: (tsv @@ to_tsquery('wrote'::text))
(5 rows)
Time: 0.429 ms
这个查询的总成本为 37.98,只比建立位图的成本(33.60)稍微大一点。
因此,GIN 索引有一个特殊的能力来限制查询结果的数量。这个阈值使用 gin_fuzzy_search_limit 参数控制,它的默认值为 0(无限制)。
我们可以手动设置这个值:
fts=# set gin_fuzzy_search_limit = 1000;
fts=# select count(*) from mail_messages where tsv @@ to_tsquery('wrote');
count
-------
5301
(1 row)
Time: 17.802 ms
fts=# set gin_fuzzy_search_limit = 10000;
fts=# select count(*) from mail_messages where tsv @@ to_tsquery('wrote');
count
-------
19717
(1 row)
Time: 56.028 ms
我们可以看到,查询返回的行数对于不同的参数值是不同的(如果使用索引访问)。这个限制不是十分的精确:可以返回多于指定行的行。这就是 fuzzy 的意思。
压缩方式
GIN 的其中一个优势是,它具有压缩的特性。首先,如果在多行中出现相同的单词,则它仅在索引中存储一次。其次,TID 以有序的方式存储在索引中,这使我们能够使用一种简单的压缩方式:列表中的下一个 TID 实际上与上一个 TID 是不同的;这个数字通常很小,与完整的六字节 TID 相比,所需的位数要小得多。
对比不同索引的大小:
-
创建一个
B-tree索引: -
GIN 建立在不同的数据类型(
tsvector而不是text)上,该数据类型较小 -
同时,
B-tree会把消息截断到 2K 以内。
fts=# create index mail_messages_btree on mail_messages(substring(body_plain for 2048));
CREATE INDEX
Time: 32709.807 ms
- 创建一个 gist 索引:
fts=# create index mail_messages_gist on mail_messages using gist(tsv);
CREATE INDEX
Time: 14651.884 ms
- 分别看一下
gin, gist, btree的大小:
fts=# select pg_size_pretty(pg_relation_size('mail_messages_tsv_idx')) as gin,
fts-# pg_size_pretty(pg_relation_size('mail_messages_gist')) as gist,
fts-# pg_size_pretty(pg_relation_size('mail_messages_btree')) as btree;
gin | gist | btree
--------+--------+--------
179 MB | 121 MB | 546 MB
(1 row)
Time: 2.961 ms
由于 GIN 索引更节省空间,我们从 Oracle 迁移到 postgresql 过程中可以使用 GIN 索引来代替位图索引。一般情况下,位图索引用于唯一值很少的字段,这对于 GIN 也是非常有效的。而且,PostgreSQL 可以基于任何索引(包括 GIN)动态构建位图。
使用 GiST 还是 GIN 呢?
GiST: http://www.postgres.cn/docs/9.6/gist.html
一般来说,GIN 在准确性和搜索速度上均胜过 GiST。如果数据更新不频繁并且需要快速搜索,则可以选择 GIN。
另一方面,如果对数据进行密集更新,则更新 GIN 的开销成本可能太大。在这种情况下,我们可以比较这两种索引,选择更适合的索引。
评论区