



solr 服务器管理界面可以查看系统状态、solr 设置、分词检测、查询索引、增减 core、查看日志等
Dashboard
Dashboard 即为仪表盘。
访问 https://solr.explorexd.com/solr/#/ 时,出现该主页面,可查看到 solr 运行时间、solr 版本,系统内存、虚拟机内存的使用情况。
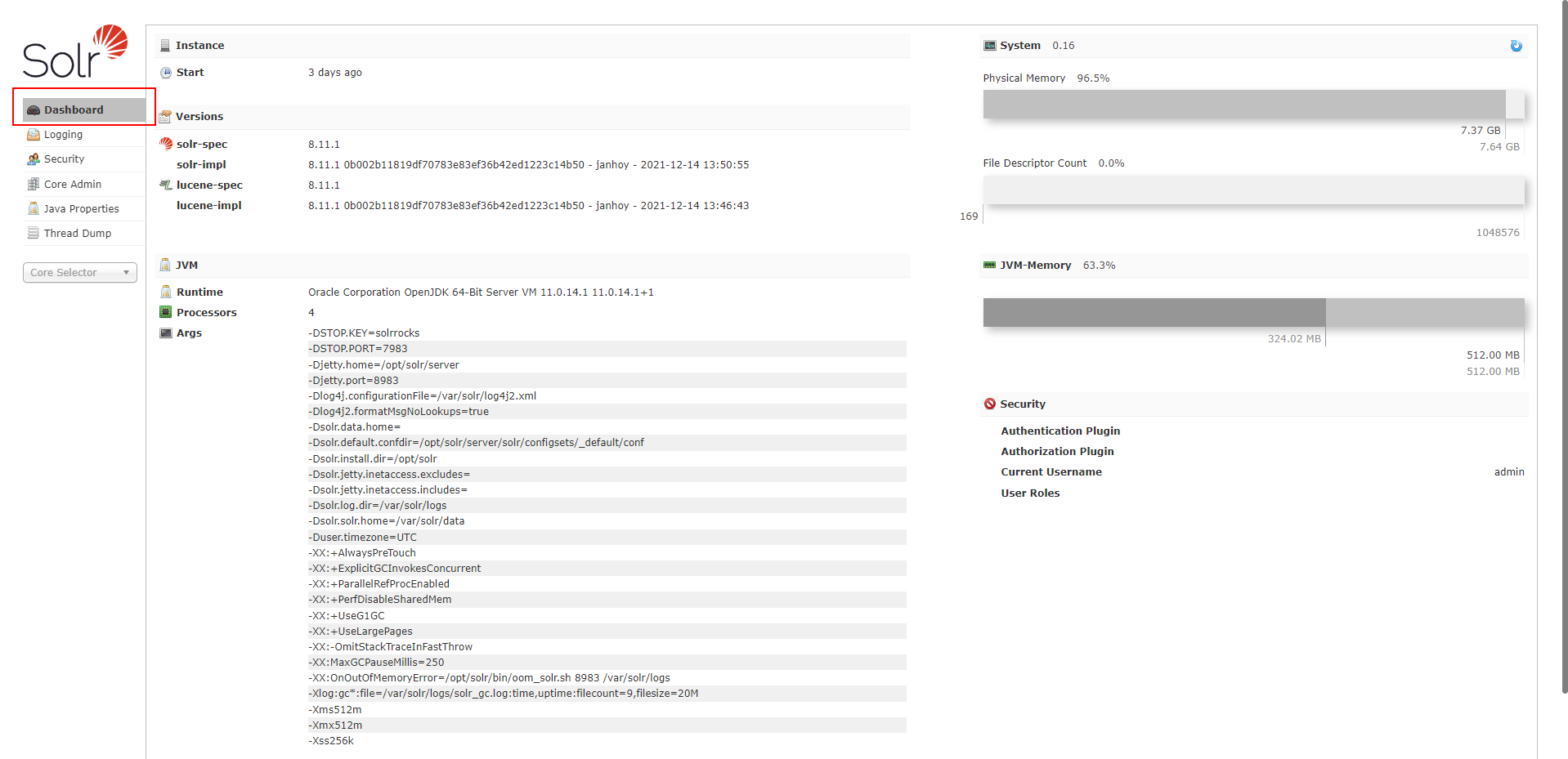
Swap Space
Swap Space 即交换空间,也叫虚拟内存。它到底有什么用呢?
给大家举个例子,假设你有一个 4G 的内存条,但是在你用着用着的时候,忽然间电脑发现这个内存条不够用了,要满,这个时候它会采用一个策略,即将这个 4G 大小的内存当中最近一段时间内用的不频繁的、使用率极低的一部分转存到磁盘上。假如说这 4 个 G 中有 1 个 G 转存到了磁盘上,内存是不是就可以剩余出 1 个 G 啦!然后再接着运行你当前的程序,而转存的这 1 个 G 就放到了你的硬盘上了(例如硬盘总共是 500 个 G,其中用 1 个 G 占内存的这一块就叫做虚拟内存,也叫交换空间)。
Logging
它会显示 Solr 运行日志信息。要想成为一名合格的程序员,你就必须得学会看日志,试想一下如果在存储数据的过程中出现了问题,你怎么知道出现了什么问题呢?这时,你就得看日志了。
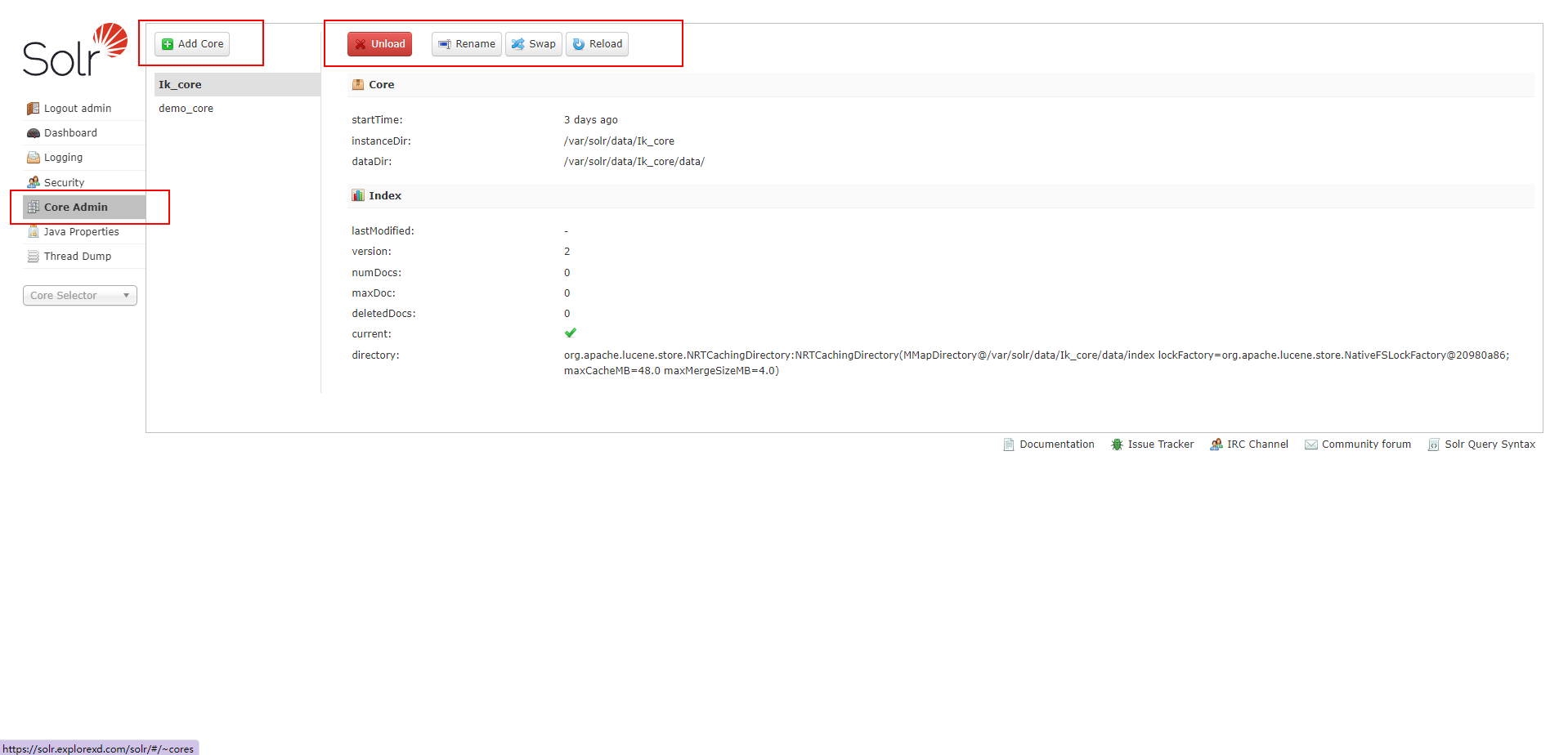
Core Admin
Solr Core 的管理界面。
Solr Core 是 Solr 的一个独立运行实例单位,它可以对外提供索引和搜索服务,一个 Solr 工程可以运行多个 Solr Core(Solr 实例),一个 Core 对应一个索引目录。要是你理解起来难的话,可以将 Solr 核管理理解成数据库管理,即一个核就是一个数据库。
- Add Core(添加核心)
- Unload(卸载核心)
- Rename(重命名核心)
- Reload(重新加载核心)
- Optimize(优化索引库)
Add Core
添加 core,主要是在 instanceDir 对应的文件夹里生成一个 core.properties 文件
- name:给 core 起的名字;
- instanceDir:与我们在配置 solr 到 tomcat 里时的 solr_home 里新建的 core 文件夹名一致;
- dataDir: 确认 Add Core 时,会在 new_core 目录下生成名为 data 的文件夹
- config:new_core 下的 conf 下的 config 配置文件 (solrconfig.xml)
- schema: new_core 下的 conf 下的 schema 文件 (schema.xml)
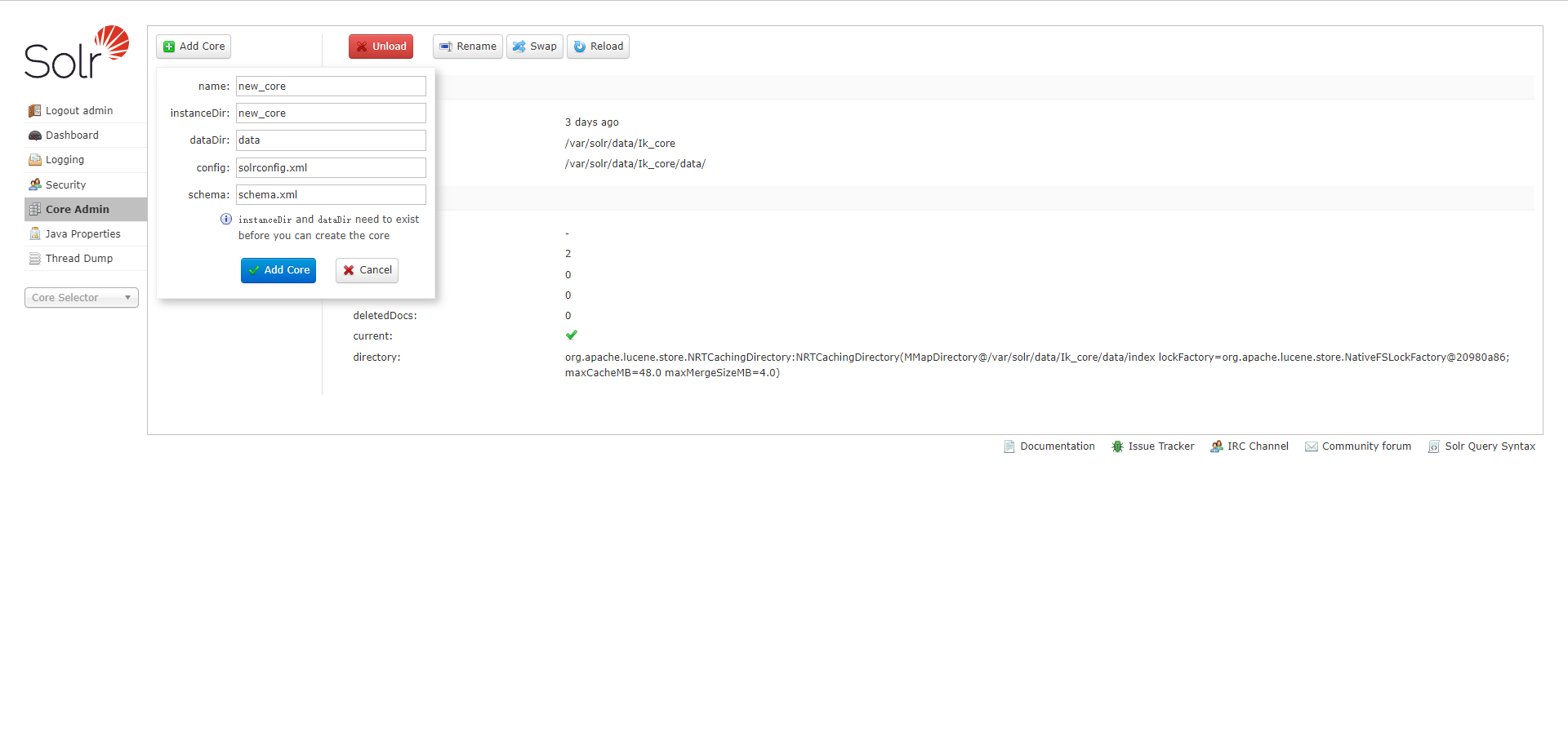
确认 Add Core 时,会在 new_core 下生成 data 文件夹,与 core.properties 文件。core.properties 文件里内容如下:
Java Properties
可查看到 java 相关的一些属性的信息,(增删改查索引都会产生一些线程),同时也可以跟踪线程运行栈信息。
Tread Dump
显示 Solr Server 中当前活跃的线程信息(增删改查索引都会产生一些线程),同时也可以跟踪线程运行栈信息。
Core Selecter
Core 选择器, 即操作具体核。
需要在 Core Admin 里添加了 core 后才有可选项,这里以已经添加好的 ik_core 为例。
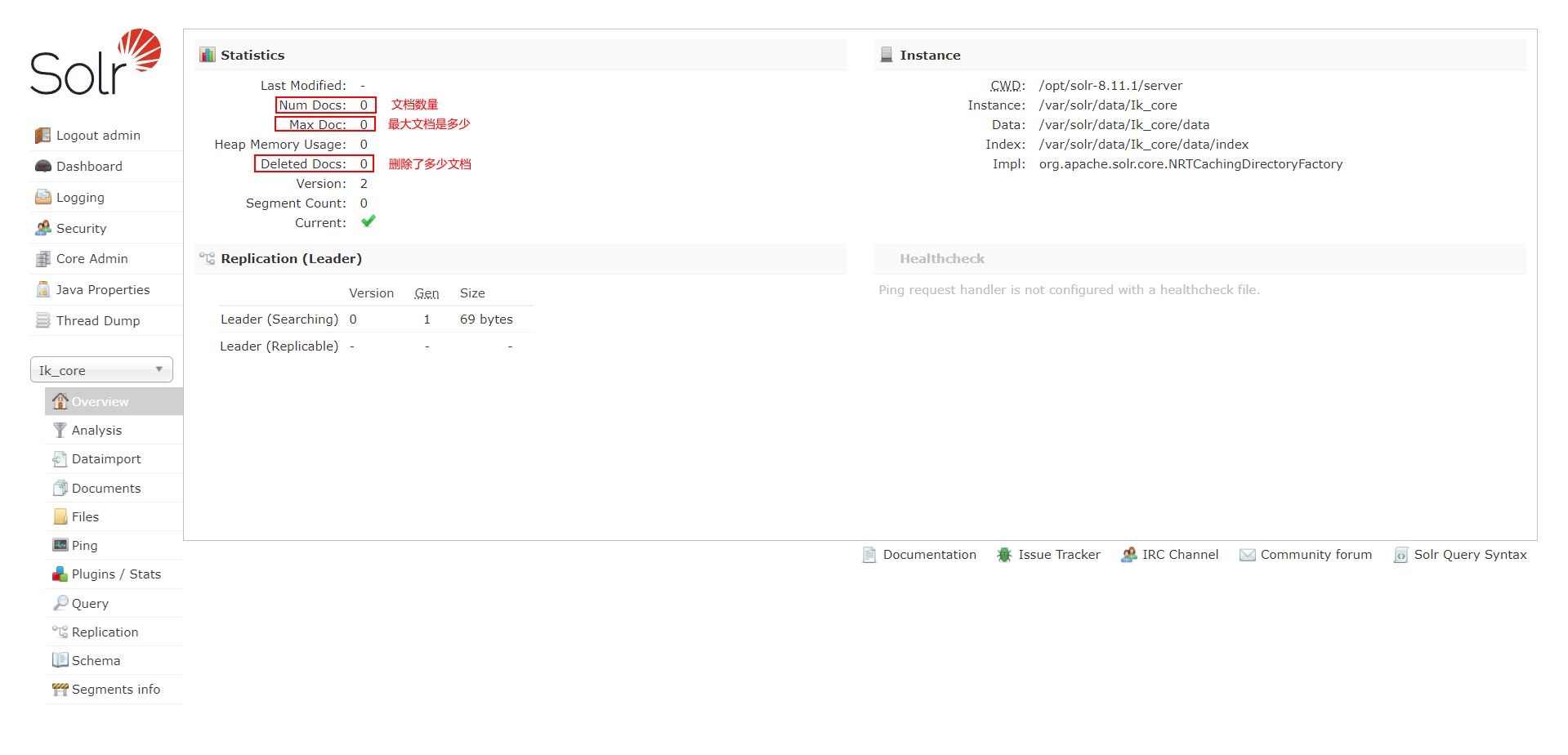
overview
概览,包含基本统计如当前文档数、实例信息如当前核心的配置目录。
Analysis
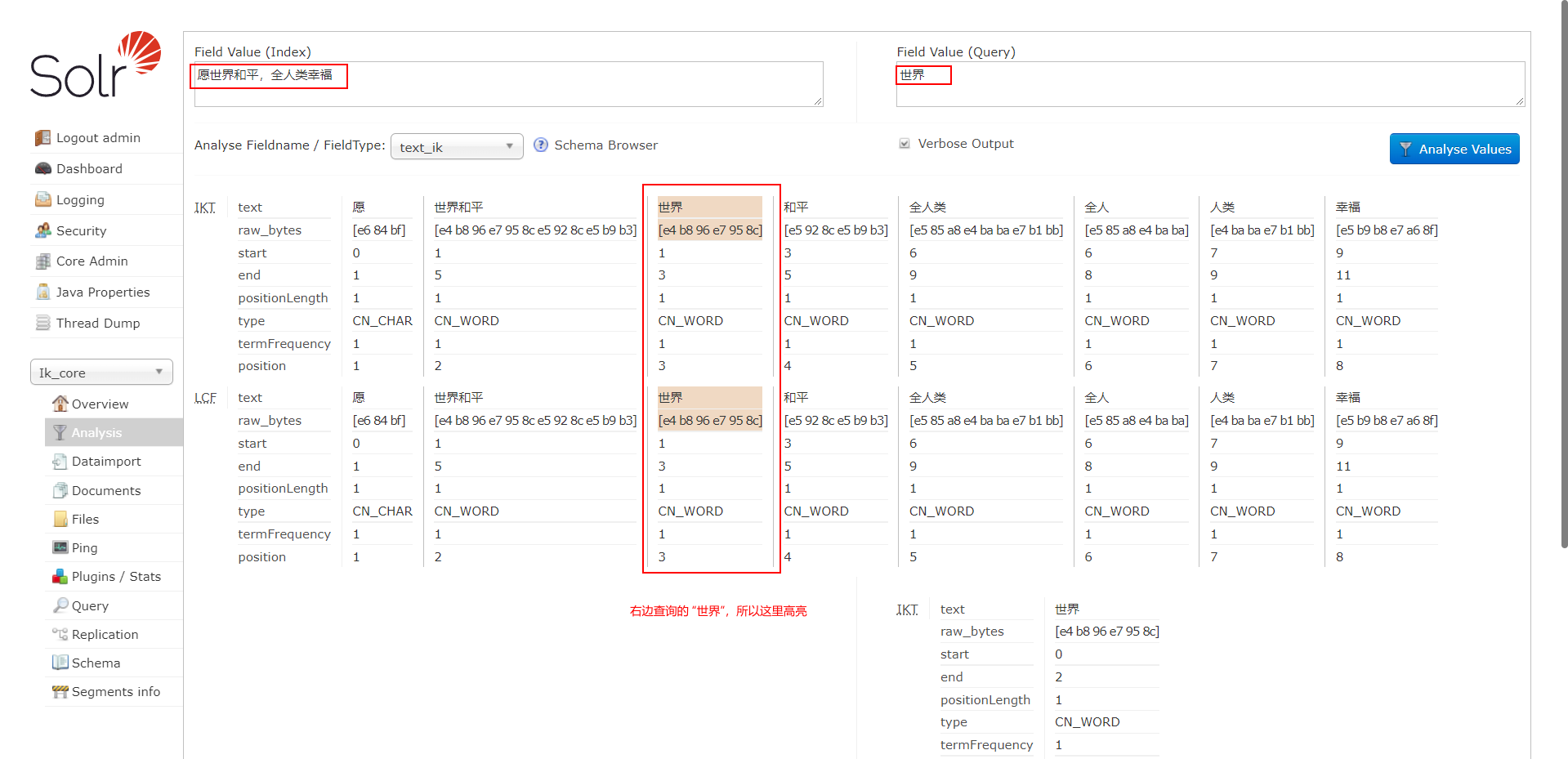
检验分词效果,如图,我们对 companyName 字段进行了分词 (至于哪些字段能分词, 取决于在 managed-schema 文件里配置该字段时的 type 是否为配置的分词器类型 text_ik)
//这里的text_ik就是下面name属性的值
<field name="companyName" type="text_ik" indexed="false" stored="true" multiValued="false" />
<!-- 配置IK分词器start -->
<fieldType name="text_ik" class="solr.TextField" positionIncrementGap="100">
<analyzer type="index">
<tokenizer class="org.wltea.analyzer.lucene.IKTokenizerFactory" useSmart="false" isMaxWordLength="false"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
<analyzer type="query">
<tokenizer class="org.wltea.analyzer.lucene.IKTokenizerFactory" useSmart="false" isMaxWordLength="false"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
</fieldType>
这里的高亮就是背景色是棕色
Dataimport
可以定义数据导入处理器,从而将关系型数据库中的数据导入到 Solr 索引库中。
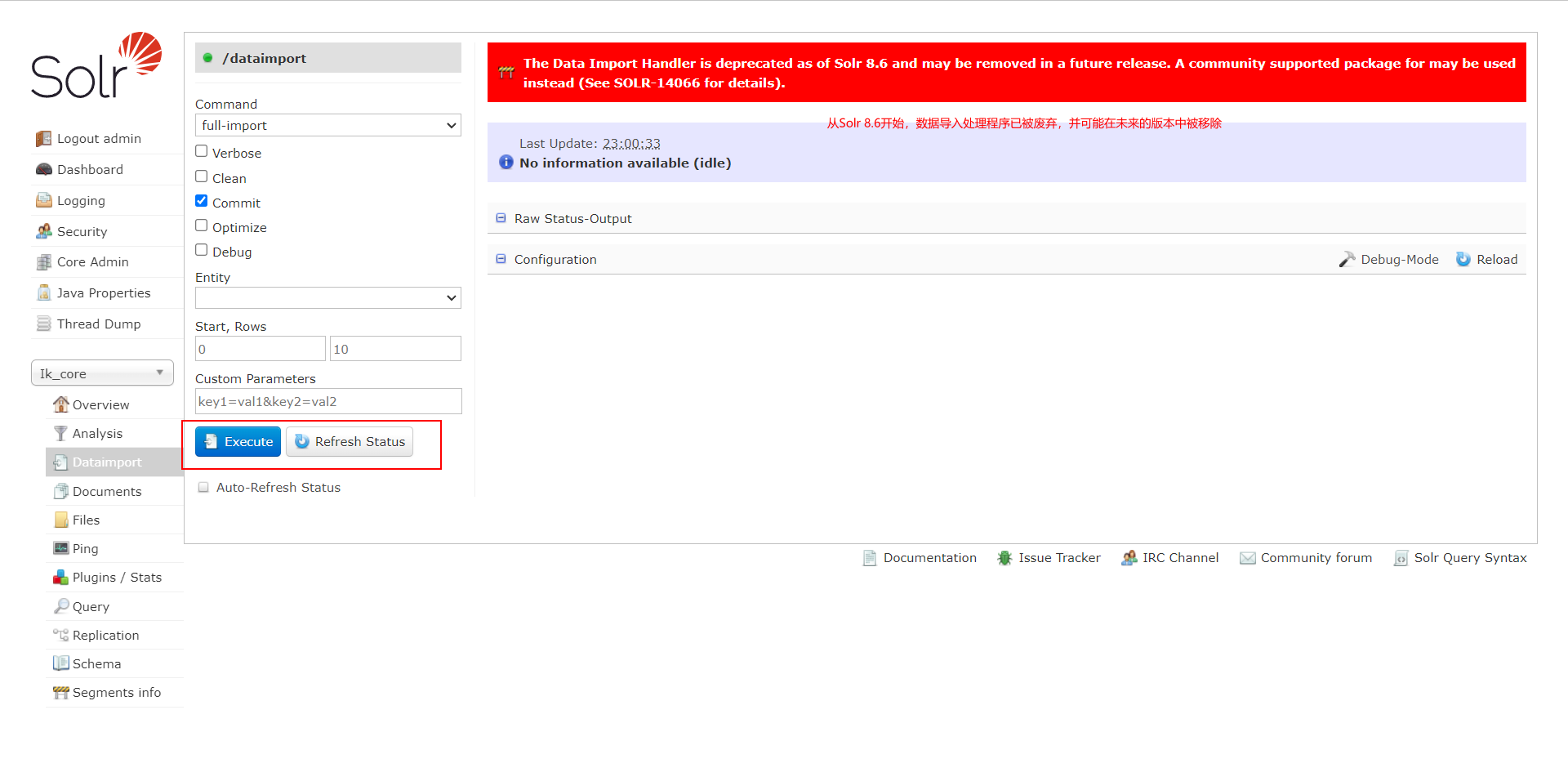
Verbose
- Clean: 在索引开始构建之前是否删除之前的索引,默认为 true
- Commit: 在索引完成之后是否提交。默认为 true
- Optimize: 是否在索引完成之后对索引进行优化。默认为 true
- Debug: 是否以调试模式运行,适用于交互式开发(interactive development mode)之中。
请注意,如果以调试模式运行,那么默认不会自动提交,请加参数“commit=true”
Entity
entity 是 document 下面的标签(data-config.xml)。使用这个参数可以有选择的执行一个或多个 entity 。使用多个 entity 参数可以使得多个 entity 同时运行。如果不选择此参数那么所有的都会被运行。
Excute
执行导入。
Refresh Status
刷新后才能看到数据发生了变化,如果刷新后数据还是 0,说明未导入。
Documents
Documents (索引文档)索引的相关操作,如: 增加,修改,删除等,例如我们要增加一个索引(companyName)的办法:
- 先要在 solr 的 /opt/solr/data/Ik_core/conf 的 managed-schema 配置文件下,增加相关的字段 field
// 这里的text_ik就是下面name属性的值
<field name="companyName" type="text_ik" indexed="false" stored="true" multiValued="false" />
```xml
<!-- 配置IK分词器start -->
<fieldType name="text_ik" class="solr.TextField" positionIncrementGap="100">
<analyzer type="index">
<tokenizer class="org.wltea.analyzer.lucene.IKTokenizerFactory" useSmart="false" isMaxWordLength="false"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
<analyzer type="query">
<tokenizer class="org.wltea.analyzer.lucene.IKTokenizerFactory" useSmart="false" isMaxWordLength="false"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
</fieldType>
否则会出现如下错误:
Status: error
Error: Bad Request
Error:
{
"responseHeader": {
"status": 400,
"QTime": 1
},
"error": {
"msg": "ERROR: [doc=126] unknown field 'companyName'",
"code": 400
}
}
- 在如下页面,选择 /update ,文档格式选择 json ,然后 submit 提交。这样 索引就增加上了。修改与增加一样,都是 /update , 删除为 /delete 。
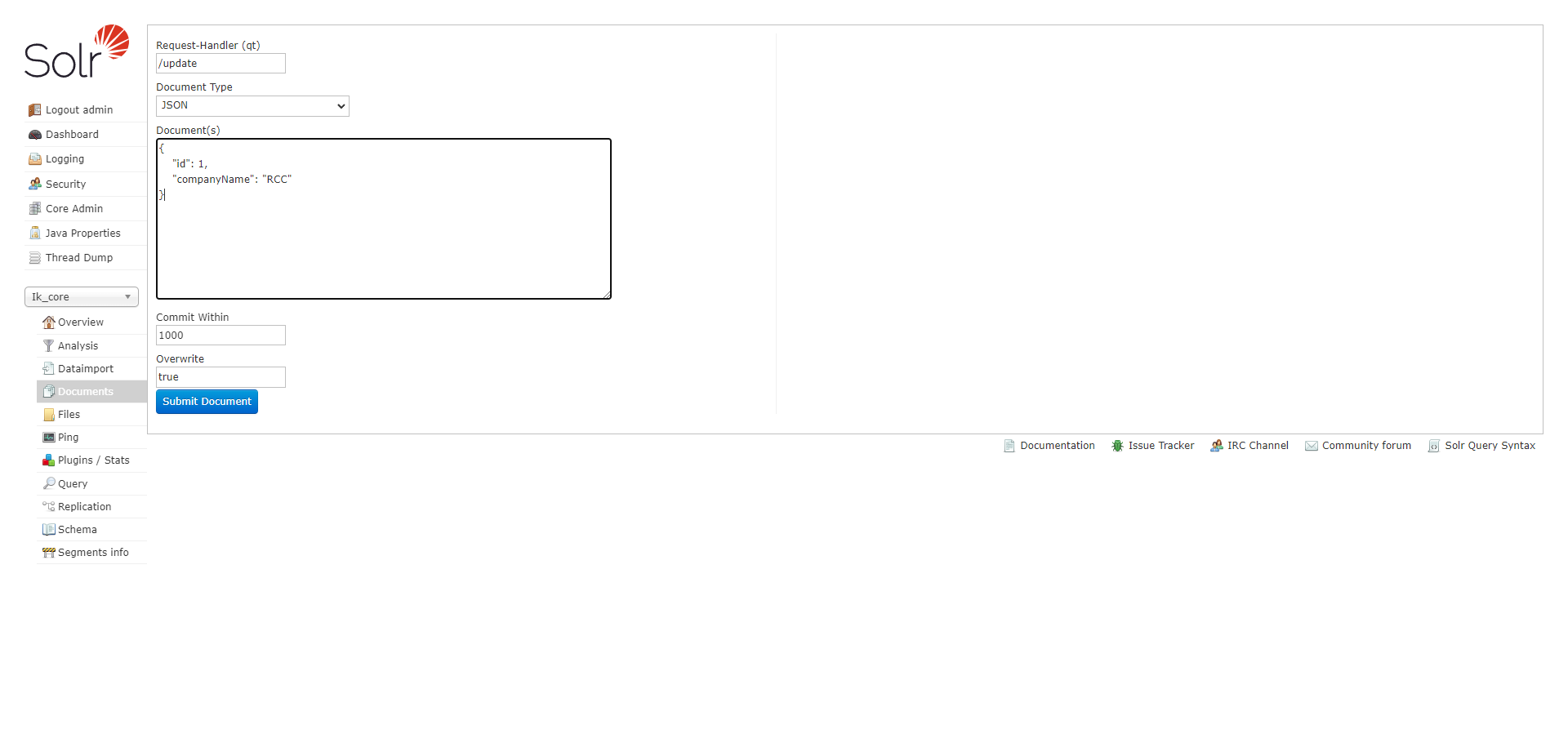
- Request-Handler(qt): 要进行的操作 (update\delete)
- Document Type:类型,有 JSON、XML 等格式
- Document(s): 内容,手动写的内容。
- Commit Within:
- Overwrite: 为 true, 说明如果 id 重复则覆盖以前的值; 为 false 说明如果 id 重复不覆盖以前的值.
- Boost: 好像是什么版本, 没用过
成功之后, 我们去 query 里查询数据就能查到我们刚添加的数据.
Files
Ik_core 下的 conf 下的相关文件, 可单击查看里面的内容.
Ping
通过此菜单可以测试 Solr 服务器是否还活着。
Plugins/Stats
Solr 自带的一些插件以及我们安装的插件的信息以及统计。
Query
查询的结果要显示哪个字段, 就得将 schema.xml 文件配置字段时的 stored 属性设为 true.
查询索引的文档,包含是否存在,排序是否正确等
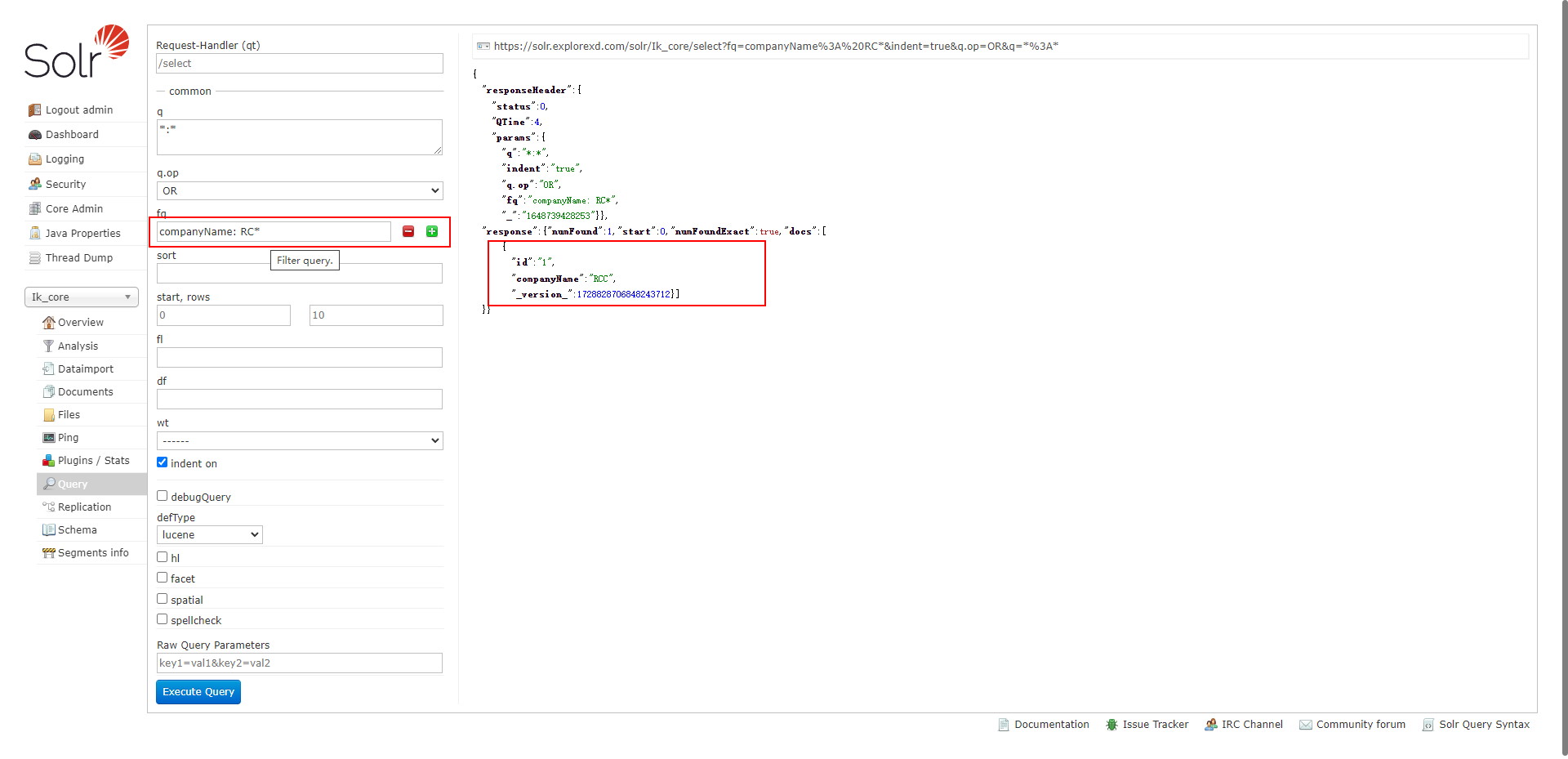
进入该页面后,直接点击 Execute Query 时,在右侧会生查回数据:
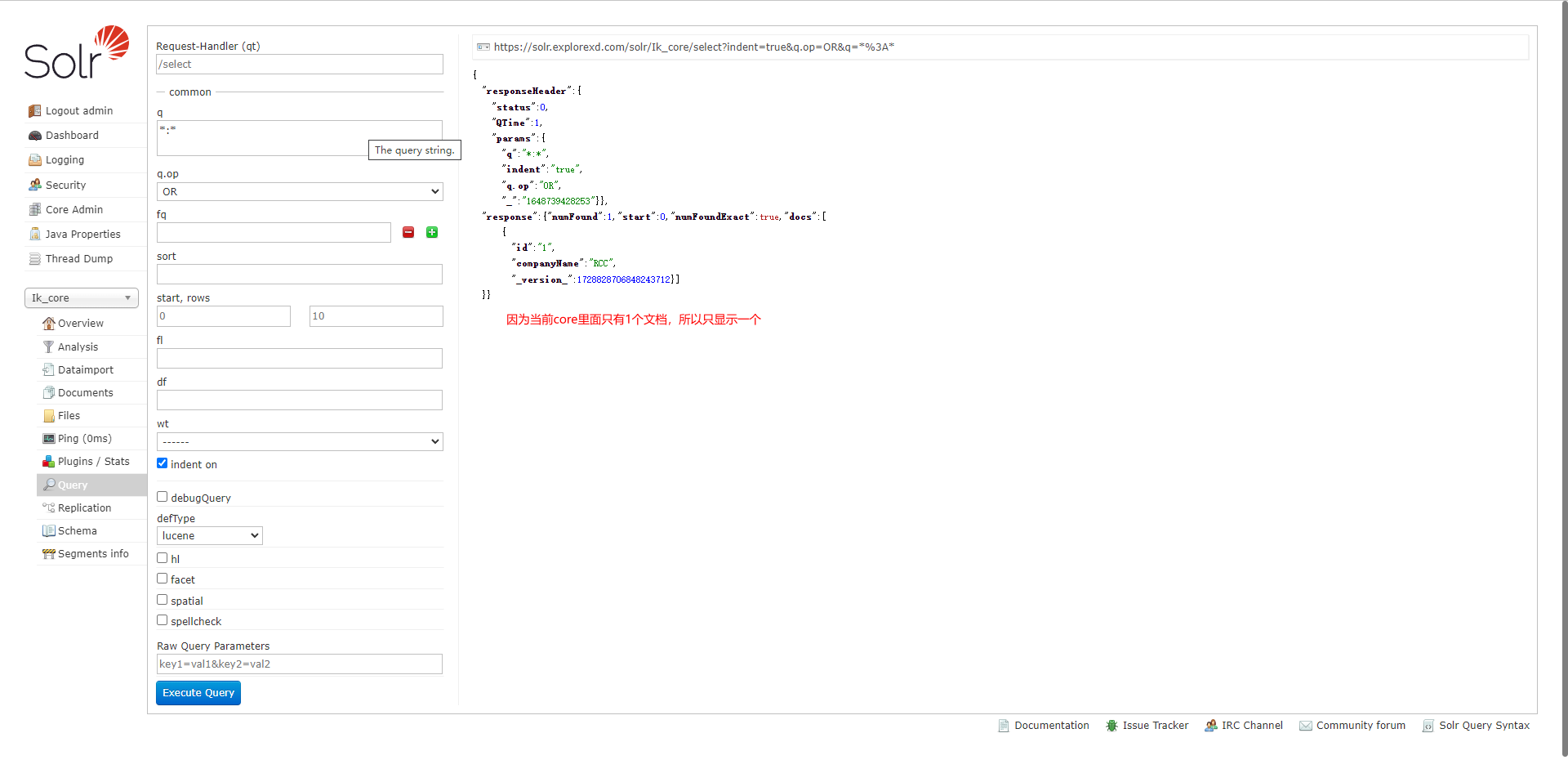
Request-Handler(qt):
- q:查询字符串(必须的)。: 表示查询所有;keyword: 东看 表示按关键字“东看”查询
- fq:filter query 过滤查询。使用 Filter Query 可以充分利用 Filter Query Cache,提高检索性能。作用:在 q 查询符合结果中同时是 fq 查询符合的 (类似求交集),例如:q=mm&fq=date_time:[20081001 TO 20091031],找关键字 mm,并且 date_time 是 20081001 到 20091031 之间的。
- sort:排序。格式如下:字段名 排序方式;如 advertiserId desc 表示按 id 字段降序排列查询结果。
- start,rows:表示查回结果从第几条数据开始显示,共显示多少条。
- fl:field list。指定查询结果返回哪些字段。多个时以空格“ ”或逗号“,”分隔。不指定时,默认全返回。
- df:default field 默认的查询字段,一般默认指定。
Raw Query Parameters:
- wt:write type。指定查询输出结果格式,我们常用的有 json 格式与 xml 格式。在 solrconfig.xml 中定义了查询输出格式:xml、json、python、ruby、php、phps、custom。
- indent:返回的结果是否缩进,默认关闭,用 indent=true | on 开启,一般调试 json,php,phps,ruby 输出才有必要用这个参数。
- debugQuery:设置返回结果是否显示 Debug 信息。
- hl:high light 高亮。hl=true 表示启用高亮
- hl.fl:用空格或逗号隔开的字段列表(指定高亮的字段)。要启用某个字段的 highlight 功能,就得保证该字段在 schema 中是 stored。如果该参数未被给出,那么就会高 亮默认字段 standard handler 会用 df 参数,dismax 字段用 qf 参数。你可以使用星号去方便的高亮所有字段。如果你使用了通配符,那么要考虑启用 hl.requiredFieldMatch 选项。
- hl.requireFieldMatch:如果置为 true,除非该字段的查询结果不为空才会被高亮。它的默认值是 false,意味 着它可能匹配某个字段却高亮一个不同的字段。如果 hl.fl 使用了通配符,那么就要启用该参数。尽管如此,如果你的查询是 all 字段(可能是使用 copy-field 指令),那么还是把它设为 false,这样搜索结果能表明哪个字段的查询文本未被找到
- hl.usePhraseHighlighter:如果一个查询中含有短语(引号框起来的)那么会保证一定要完全匹配短语的才会被高亮。
- hl.highlightMultiTerm:如果使用通配符和模糊搜索,那么会确保与通配符匹配的 term 会高亮。默认为 false,同时 hl.usePhraseHighlighter 要为 true。
- facet:分组统计,在搜索关键字的同时, 能够按照 Facet 的字段进行分组并统计。
- facet.query:Facet Query 利用类似于 filter query 的语法提供了更为灵活的 Facet. 通过 facet.query 参数,可以对任意字段进行筛选。
- facet.field:需要分组统计的字段,可以多个。
- facet.prefix:表示 Facet 字段值的前缀。比如 facet.field=cpu&facet.prefix=Intel,那么对 cpu 字段进行 Facet 查询,返回的 cpu 都是以 Intel 开头的, AMD 开头的 cpu 型号将不会被统计在内。
- spellcheck:拼写检查。
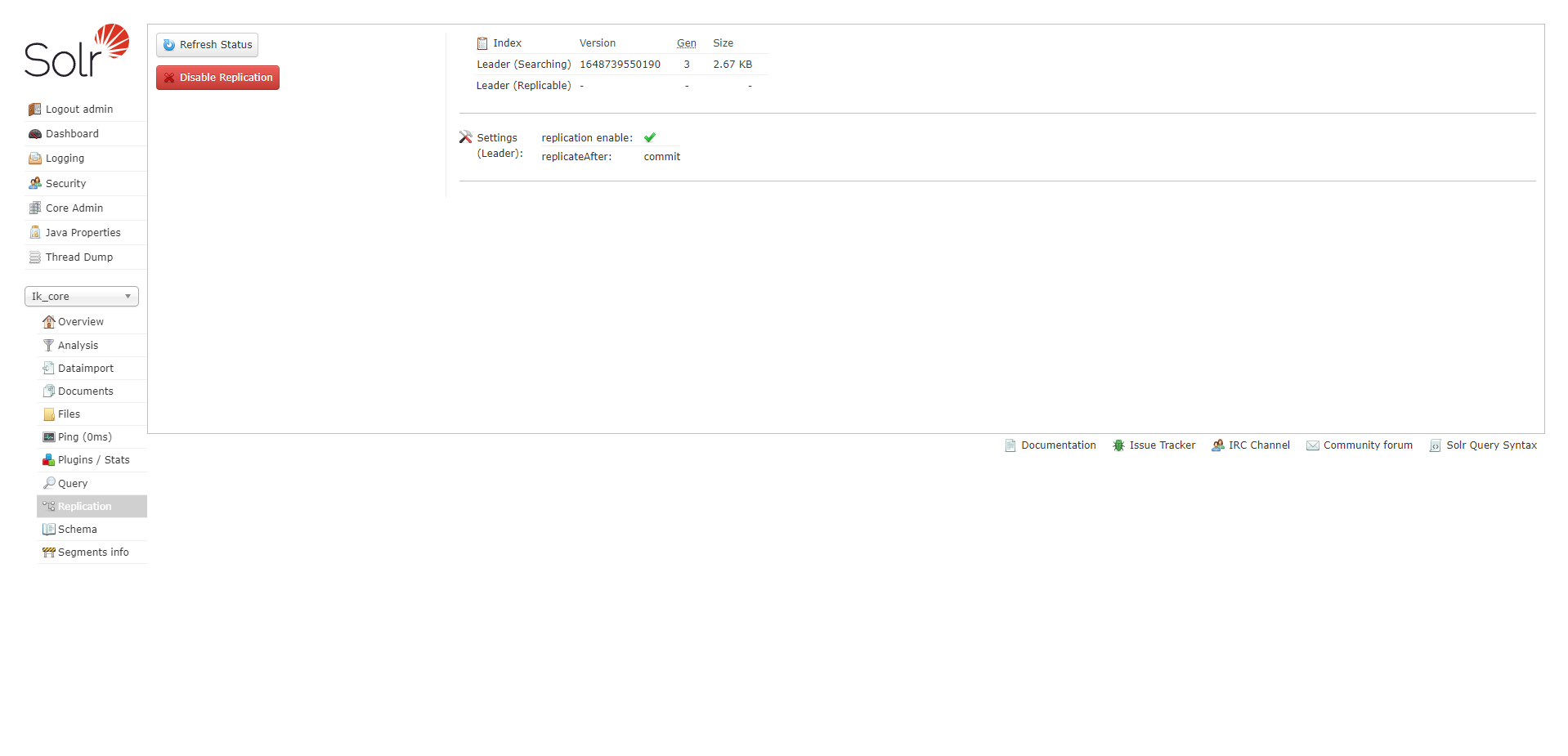
Replication
显示你当前 Core 的副本,并提供 disable/enable 功能。
Schema
其实它就是 managed-schema 里面的配置,里面会有大量的域。
参考
https://www.w3cschool.cn/solr_doc/solr_doc-fbc32fuv.html
https://liayun.blog.csdn.net/article/details/105489726
https://zhuanlan.zhihu.com/p/85670678
评论区