



schema 介绍
schema 翻译过来即模式,它是集合 / 内核中字段的定义,主要是让 Solr 知道集合 / 内核包含哪些字段、字段的数据类型以及该字段是否存储索引。
schema 文件是在 SolrConfig 中的架构工厂定义,有两种定义模式,也就是说 Solr 中提供了两种方式来配置 schema,但两者只能选其一。
两种定义模式
默认的托管模式
Solr 默认使用的就是托管模式。也就是说当在 solrconfig.xml 配置文件中没有显式声明 <schemaFactory/> 时,Solr 隐式地使用 ManagedIndexSchemaFactory,它是默认的 mutable,并且将模式信息保存在一个名为 managed-schema 文件中。
<schemaFactory class="ManagedIndexSchemaFactory">
<bool name="mutable">true</bool>
<str name="managedSchemaResourceName">managed-schema</str>
</schemaFactory>
当然,也可以显式的声明 schema 文件,但是,当显式的声明 schema 文件的时候,文件的名字不能是 managed-schema 也不能是 schema.xml。同时 schema 文件的名字要与 solrconfig.xml 配置文件中声明的 schema 文件名一样。
经典的 schema.xml 模式
这种模式的配置方式是在 solrconfig.xml 配置文件中显式配置一个 ClassicIndexSchemaFactory。
<schemaFactory class="ClassicIndexSchemaFactory"/>
ClassicIndexSchemaFactory 需要使用 schema.xml 配置文件,并且不允许在运行时对架构进行任何编程式更改。而且该 schema.xml 文件必须手动编辑,编辑完后需要重载集合 / 内核才会生效。
两种模式的区别
- 两种模式下,schema 文件的格式形式不同,默认的托管模式下的 schema 文件名字必须是 managed-schema;而经典的 schema.xml 模式下的 schema 文件名字必须是 schema.xml。
- 两种模式下,solrconfig.xml 配置文件中的
声明的方式也不同。
两种模式之间的相互切换
这两种模式之间是可以切换的,比如用于升级操作,从旧版本到新版本的升级。
从经典的 schema.xml 模式切换到默认的托管模式
只需要将 solrconfig.xml 配置文件中显示配置的 <schemaFactory class="ClassicIndexSchemaFactory"/> 删除或注释掉,然后重新启动 Solr 服务器即可。
当 Solr 服务器启动的时候,会检测是否存在 managed-schema 文件,如果存在,那么这个 managed-schema 文件就是将要被读取的文件;如果 managed-schema 文件不存在,那么 Solr 服务器就会将 schema.xml 文件中的内容读取并将内容写入新建的 managed-schema 文件,然后将 schema.xml 文件重命名为 schema.xml.bak。
从默认的托管模式切换到经典的 schema.xml 模式
从默认的托管模式切换到经典的 schema.xml 模式,只须三步即可实现。
- 将 managed-schema 文件重命名为 schema.xml;
- 在 solrconfig.xml 配置文件中显示的配置
; - 重新启动 Solr 服务器。
managed-schema 配置文件详解
在 Solr Core 内的 conf 目录下有两个配置文件是我们要掌握的,一个是 solrconfig.xml 核心配置文件,另外一个就是 managed-schema 配置文件。

所以,managed-schema 配置文件中配置的到底是些什么东西呢?
该配置文件在 Solr Core 的 conf 目录下,它是 Solr 数据表配置文件,它定义了加入索引的数据的数据类型,主要包括很多 field 字段、唯一 ID、fieldType 字段类型和其他的一些缺省设置。我们先了解下 managed-schema 配置文件的大致结构。
<?xml version="1.0" encoding="UTF-8" ?>
<schema version="1.6">
<field .../>
<dynamicField .../>
<uniqueKey>id</uniqueKey>
<copyField .../>
<fieldType ...>
<analyzer type="index">
<tokenizer .../>
<filter ... />
</analyzer>
<analyzer type="query">
<tokenizer .../>
<filter ... />
</analyzer>
</fieldType>
</schema>
field(字段)
字段定义
其实,在 managed-schema 配置文件中配置了大量的域。
<field name="id" type="string" indexed="true" stored="true" required="true" multiValued="false" />
<!-- docValues are enabled by default for long type so we don't need to index the version field -->
<field name="_version_" type="plong" indexed="false" stored="false"/>
<!-- If you don't use child/nested documents, then you should remove the next two fields: -->
<!-- for nested documents (minimal; points to root document) -->
<field name="_root_" type="string" indexed="true" stored="false" docValues="false" />
<!-- for nested documents (relationship tracking) -->
<field name="_nest_path_" type="_nest_path_" /><fieldType name="_nest_path_" class="solr.NestPathField" />
<field name="_text_" type="text_general" indexed="true" stored="false" multiValued="true"/>
选取几个域进行详细介绍。先来看看如下配置是个什么意思?
<field name="_version_" type="plong" indexed="false" stored="false"/>
以上配置的意思就是说配置了一个域,名字叫 _version_,类型是 plong 类型(注意:这里的 plong 是别名)。以 plong 为关键字继续在 managed-schema 配置文件中查找,你就能很快找到它的位置了。
<fieldType name="pint" class="solr.IntPointField" docValues="true"/>
<fieldType name="pfloat" class="solr.FloatPointField" docValues="true"/>
<fieldType name="plong" class="solr.LongPointField" docValues="true"/>
<fieldType name="pdouble" class="solr.DoublePointField" docValues="true"/>
<fieldType name="pints" class="solr.IntPointField" docValues="true" multiValued="true"/>
<fieldType name="pfloats" class="solr.FloatPointField" docValues="true" multiValued="true"/>
<fieldType name="plongs" class="solr.LongPointField" docValues="true" multiValued="true"/>
<fieldType name="pdoubles" class="solr.DoublePointField" docValues="true" multiValued="true"/>
<fieldType name="random" class="solr.RandomSortField" indexed="true"/>
这就说明了名字为 _version_ 的这个域,是 LongPoint 类型的。从该域的配置中还可以看到 indexed 和 stored 属性明确地设置为了 false,这表明该域既不索引也不存储。
再继续往下看,会看到有如下这样一个配置:
<field name="id" type="string" multiValued="false" indexed="true" required="true" stored="true"/>
以上配置的是 id 域,可以发现该域中 required 属性的值为 true(即必须),它就相当于数据库表中的主键 id。Lucene 是自己生成,类似自增长;Solr 是在 managed-schema 配置文件中进行配置,需要我们自己进行指定。总而言之,以后在用 Solr 保存一个数据的时候,一定记得要给 id。
接着再继续往下看,会看到有如下这样一个配置:
<field name="title" type="text_ik" indexed="true" stored="true" multiValued="true"/>
可以看到以上配置的 title 域中 multiValued 属性的值为 true,这意味着什么呢?如果某个域要存储多个值,那么 multiValued 属性的值设置为 true 即可。Solr 允许一个域存储多个值,比如存储一个用户的好友 id(多个),商品的图片(多个,大图和小图)。就拿 title 域来说,我们可以向该域中存储多个值,就像下面这样。
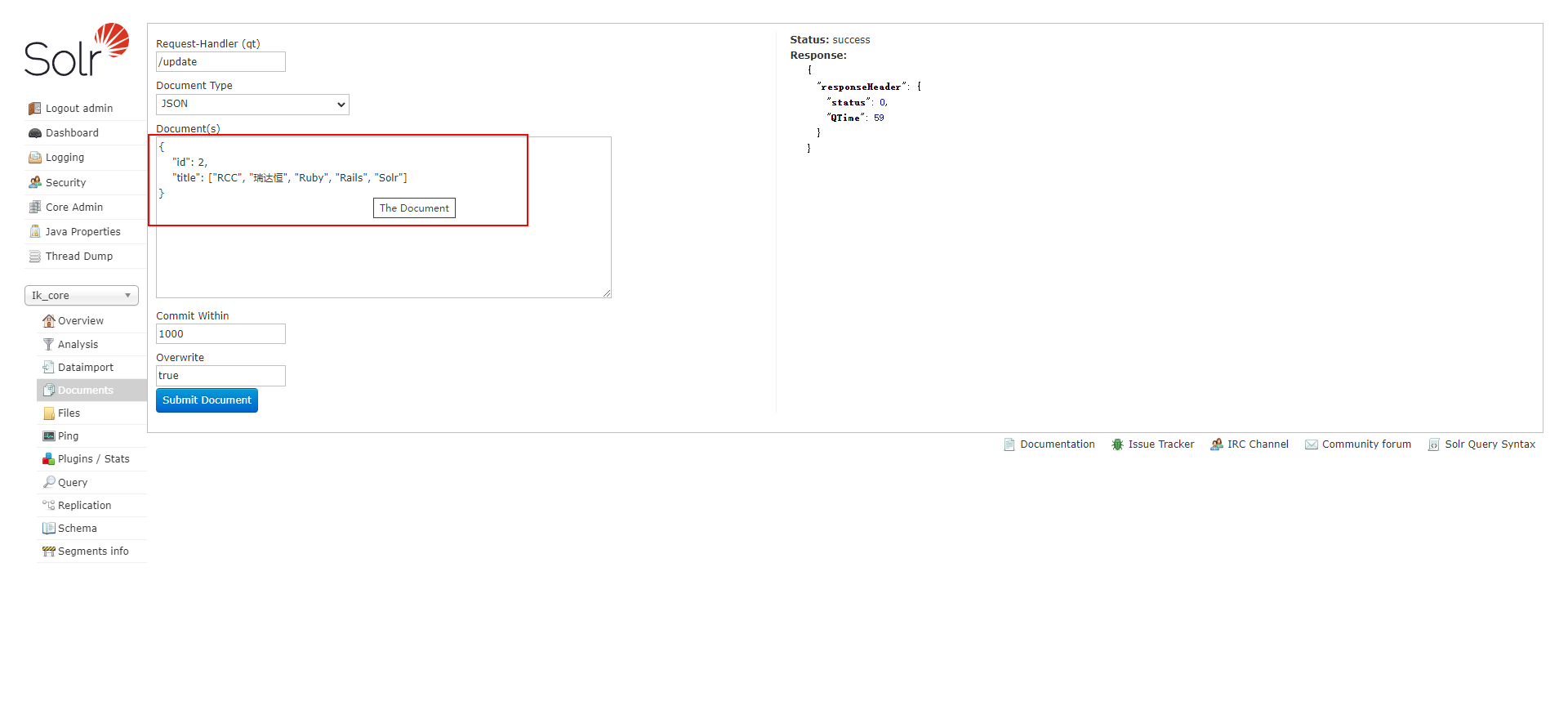
最后使用 Solr 查询,我们可以看出返回给客户端的是数组,类似于下图这样。
field 属性
字段定义可以具有以下属性:
name:该字段的名称。字段名称只能由字母、数字或下划线字符组成,不能以数字开头。目前这并不是严格执行的,但其他字段名称将不具备所有组件的第一类支持,并且不保证向后的兼容性。以下划线开头和结尾的名字为保留字段名,如 _version_。每个字段都必须要有一个 name。
type:字段的 fieldType 名,而且必须,该属性的值为 fieldType 标签中定义的 name 属性的值;
default:默认值,非必须。如果提交的文档中没有该字段的值,则自动会为文档添加这个默认值。相当于传统数据库中的字段默认值。
除此之外,字段还有很多可选属性,如下列表所示。

其实,字段还有很多可选属性我没介绍到,主要是这些属性咱也不熟 ~~~ 不过,要注意以下四点:
- 上述属性是 field 字段本身就有的;
- field 字段中有一个 type 属性,该属性会指向一个 fieldType 标签,该标签内部也会有上述描述的那些属性;
- 若 field 中某个属性在引用的 fieldType 中也存在,则以 field 中定义的属性为准;
- 一般来说,使用 fieldType 中定义的属性就已经够用了,如果字段比较特殊,可以在字段层面定义属性,用来覆盖掉 fieldType 中的属性。
dynamicField
为了防止以上的域依然不够用,所以这才有了 dynamicField(动态字段)。如果模式中有近百个字段需要定义,其中有很多字段的定义都是相同的,那么重复地定义就十分的麻烦,因此可以定一个规则,字段名以某前缀开头或结尾的是相同的定义配置,那这些重复字段就只需要配置一个,保证提交的字段名称遵守这个前缀或后缀即可,这就是动态字段。例如,整型字段都是一样的定义,则可以定义一个如下的动态字段。
<dynamicField name="*_i" type="pint" indexed="true" stored="true"/>
注意:动态字段只能用符号 * 通配符进行表示,且只有前缀和后缀两种方式。
其实说白了,动态字段就是不用指定具体的名称,只须定义字段名称的规则即可。例如,定义一个 dynamicField,name 为 *_s,type 为 string,那么在使用这个字段的时候,任何以 _s 结尾的字段都被认为是符合这个定义的,比方说 name_s、gender_s、school_i 等。
多说无益,还是用一个例子来说明一下。查看 managed-schema 配置文件,会发现有如下一个 dynamicField。
<dynamicField name="*_t" type="text_general" indexed="true" stored="true" multiValued="false"/>
那么在创建索引时,就可以像下图这样做了。
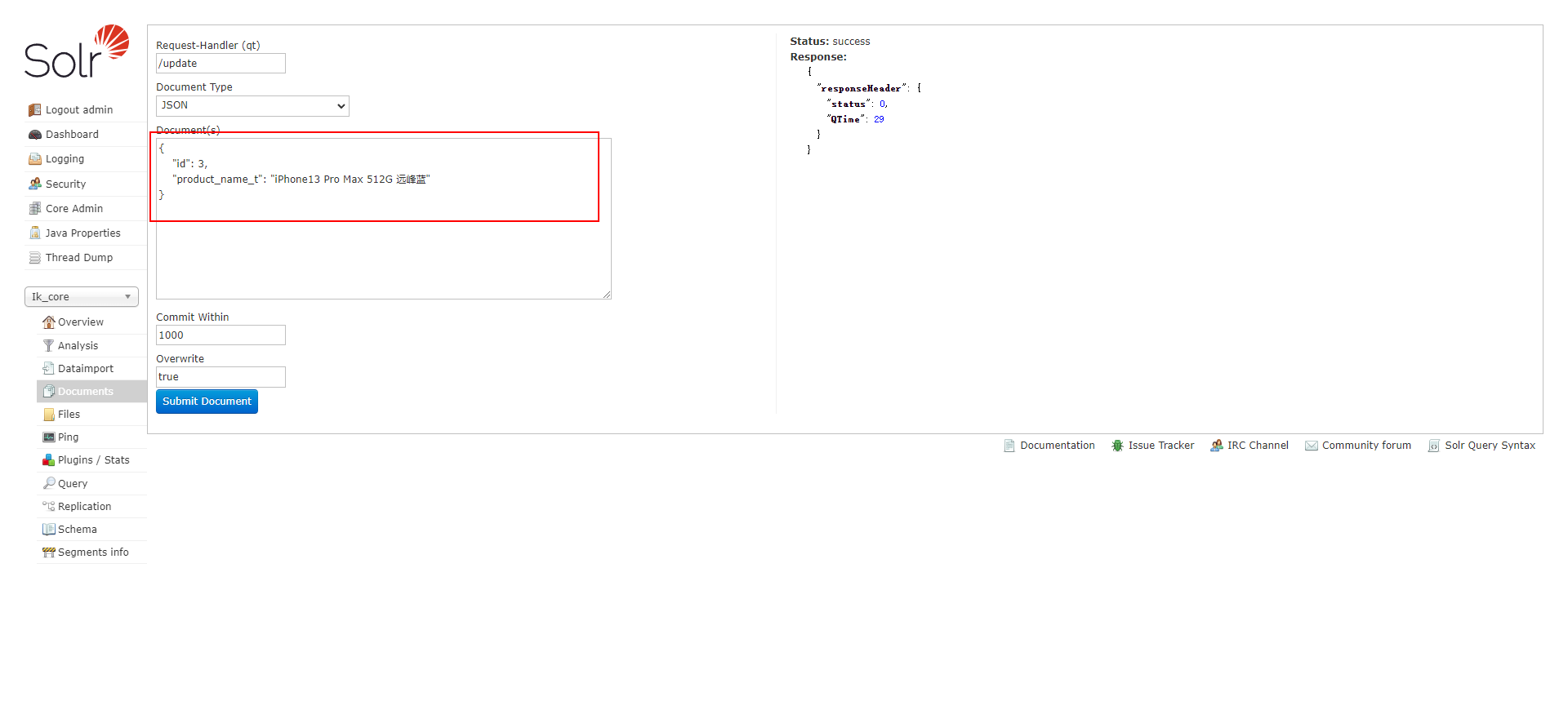
然后再搜索一下索引,此时,就能看到返回给客户端的结果就是下图这样子的了。
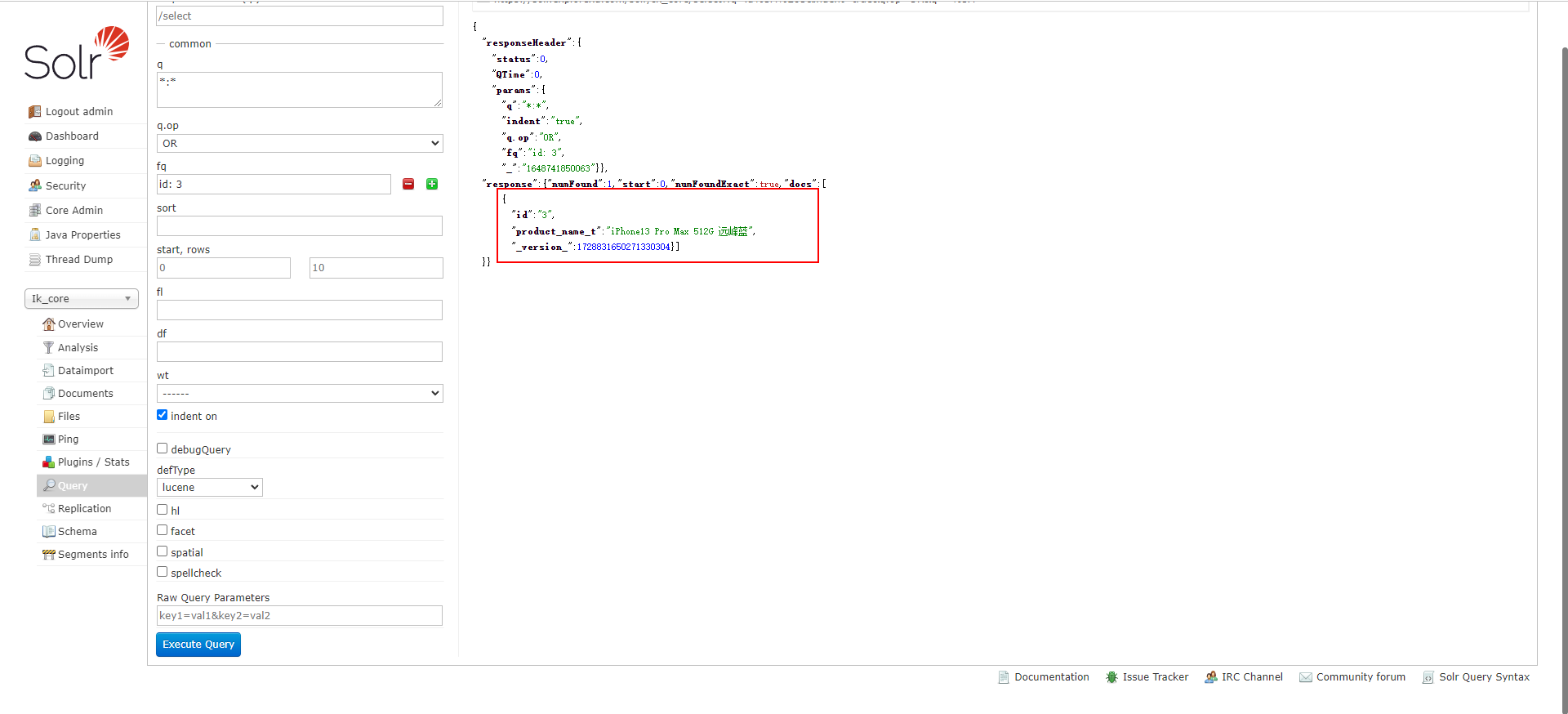
你有没有思考过这样一个问题:提前设定好这些域的目的到底是什么?
managed-schema 配置文件中配置的域,就是我们要使用的域,意思就是说我们在使用 Solr 进行开发,在用任何一个域的时候,这个域一定得要在 managed-schema 配置文件中提前配置好。如果你曾经没配置过,而且又用了一个没配置过的域,那么这时就会报错,因为 Solr 服务器本身就不认识这个域。这就是为什么 Solr 要在 managed-schema 配置文件帮我们配置大量的域的原因。
虽然 managed-schema 配置文件中配置了很多域,可以直接使用,但是也可以自己自行配置,即自定义域。例如,可以自定义一个如下域。
这样,就可以像下图所示那样创建索引了。
<!-- 自定义的域 -->
<field name="companyName" type="text_ik" indexed="true" stored="true" multiValued="false" />
<field name="title" type="text_ik" indexed="true" stored="true" multiValued="true" />
结论:没有配置过的域不能用,配置过的域就能用。
uniqueKey(唯一主键)
Solr 中默认定义唯一主键 key 为 id 域,如下所示。
<uniqueKey>id</uniqueKey>
Solr 在删除、更新索引时使用 id 域进行判断,当然了,我们也可以自定义唯一主键,例如指定商品 ID 为唯一主键(类似于传统数据库的主键 ID)。
<!-- 指定商品ID为唯一键,类似于传统数据库的主键ID -->
<uniqueKey>productId<uniqueKey>
需要注意的地方:
- 在创建索引时必须指定唯一约束;
- 这里的唯一主键是指业务主键,并不是 Document 的主键;
- 唯一主键字段不可以是保留字段、复制字段,且不能分词。
copyField(复制字段)
在 managed-schema 配置文件中,你会看到如下配置。
<copyField source="name" dest="text" />
<copyField source="content" dest="text" />
以上就是复制字段,这个字段是什么意思,又有什么作用呢?
复制字段允许将一个或多个字段的值填充到一个字段中。它的用途通常来说有两种:
- 将多个字段内容填充到一个字段,来进行搜索;
- 对同一个字段内容进行不同的分词过滤,创建一个新的可搜索字段。
例子:
比如,现在有一个需求,想要输入关键字搜索标题(title)和内容(content)。为了解决这样的需求,首先应定义如下几个名字为 title、content 以及 text 的域。
<field name="title" type="text_ik" indexed="true" stored="true" multiValued="true" />
<field name="content" type="text_ik" indexed="false" stored="true" multiValued="true" />
<field name="text" type="text_ik" indexed="true" stored="false" multiValued="true" />
然后,将 title 域和 content 域中的内容复制到 text 域中,如下所示。
<copyField source="name" dest="text" />
<copyField source="content" dest="text" />
这样就定义好了一个复制字段。现在根据关键字只搜索 text 域中的内容就相当于搜索 title 域和 content 域了。
总结:
复制域,就是说白了,当你搜索的时候,想搜两个域,但能不能把这两个域合并在一下,就搜一个域呢!
fieldType(字段类型)
浏览 managed-schema 配置文件时,或许会看到如下配置。
<fieldType name="text_general" class="solr.TextField" positionIncrementGap="100" multiValued="true">
<analyzer type="index">
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt" />
<!-- in this example, we will only use synonyms at query time
<filter class="solr.SynonymGraphFilterFactory" synonyms="index_synonyms.txt" ignoreCase="true" expand="false"/>
<filter class="solr.FlattenGraphFilterFactory"/>
-->
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
<analyzer type="query">
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt" />
<filter class="solr.SynonymGraphFilterFactory" synonyms="synonyms.txt" ignoreCase="true" expand="true"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
</fieldType>
可以看到以上 fieldType 节点包含有 name、class、positionIncrementGap 等一些属性。
name:字段类型fieldType的名称(必填)。该值用于字段定义中的 type 属性中。强烈建议名称仅包含字母、数字或下划线字符,不能以数字开头;class:用于存储和索引此类型数据的实现类的类名(必填)。关于该属性的取值,你应注意如下两点:- 可以用 "solr" 作为前缀包含的类名称。Solr 会自动找出哪些软件包可以搜索这个类实现类负责确保字段被正确处理。在 managed-schema 配置文件中,字符串 solr 是
org.apache.solr.schema或者org.apache.solr.analysis的简写形式。所以,solr.TextField实际上是org.apache.solr.schema.TextField; - 如果你使用的是第三方类,那么可能需要具有完全限定的类名称。比如,
solr.TextField的完全限定类名是org.apache.solr.schema.TextField。
- 可以用 "solr" 作为前缀包含的类名称。Solr 会自动找出哪些软件包可以搜索这个类实现类负责确保字段被正确处理。在 managed-schema 配置文件中,字符串 solr 是
positionIncrementGap:对于多值字段,指定多个值之间的距离,这可以防止虚假词组匹配。此值相当于 Lucene 的短语查询设置 slop 值。
在定义 fieldType 的时候,最重要的就是定义这个类型的数据在建立索引和进行查询的时候要使用的分析器 analyzer,包括分词和过滤。仔细看以上名为 text_general 的 fieldType,你将会看到:
- 在索引分析器中,使用的是
solr.StandardTokenizerFactory标准分词器、solr.StopFilterFactory停用词过滤器以及solr.LowerCaseFilterFactory小写过滤器; - 在搜索分析器中,使用的是
solr.StandardTokenizerFactory标准分词器、solr.StopFilterFactory停用词过滤器以及solr.LowerCaseFilterFactory小写过滤器,除此之外,这里还用到了solr.SynonymGraphFilterFactory同义词过滤器。
评论区